En este estudio comparto cómo la indexación masiva en Google funcionó en un proyecto real, publiqué más de mil páginas de una sola vez en una web de tamaño pequeño y analicé el impacto en Google Search Console.
La pieza pone el foco en lo importante, esto es la calidad del contenido, arquitectura interna y una orquestación técnica que no estrangule el servidor. Aporto métricas reales (1,3k+ URLs indexadas casi al instante, 357k impresiones y 8,29k clics en pocos días) y un método paso a paso para replicarlo con seguridad.
Índice
- Qué es la indexación masiva en Google
- ¿Publicar 1.000+ páginas de golpe es malo para SEO?
- El papel del crawl budget cuando se publica en masa
- Sitemaps para despliegues grandes (por lotes)
- Indexing API: cuándo sí y cuándo no
- Cómo pedí la indexación y qué pasó (mi experimento)
- Checklist técnico para publicar 1.000+ páginas de golpe
- Qué métricas monitoricé en Search Console
- Errores comunes a escala
- Preguntas frecuentes
- Siguiente paso
- Conclusión
Qué es la indexación masiva en Google
Definición (snippet objetivo). La indexación masiva en Google es la práctica de publicar y enviar a rastrear cientos o miles de páginas de una sola vez. No resulta problemática si el contenido es de alta calidad y el sitio soporta el rastreo, la clave es segmentar bien los sitemaps, mantener una arquitectura interna clara y controlar el crawl budget con métricas.
En ese contexto, la pregunta interesante no es ¿cuántas páginas son demasiadas?, sino ¿qué señales envío a Google para que descubra, priorice y conserve lo que acabo de lanzar?. Mi enfoque fue tratar el despliegue como una release técnica, es decir, todo medido, todo versionado y con capacidad de reacción ante picos.
¿Publicar 1.000+ páginas de golpe es malo para SEO?
No. El volumen por sí mismo no es sinónimo de spam ni genera una penalización automática. Lo que sí importa es la calidad (contenido útil y diferenciado), la coherencia técnica (URLs canónicas, paginaciones, faceteado) y que el burst de rastreo no colapse el servidor. Las directrices técnicas de Google insisten en la relación entre capacidad del sitio, demanda de rastreo y calidad de las URLs.
- Riesgo 1: contenido pobre o duplicado. Lanzar plantillas sin valor real diluye señales y desperdicia presupuesto de rastreo.
- Riesgo 2: faceteado ilimitado. Filtros que generan combinaciones infinitas sin utilidad saturan el rastreo.
- Riesgo 3: canibalización. Múltiples URLs atacando la misma consulta pueden competir entre sí.
- Riesgo 4: enlazado débil. Si las nuevas páginas quedan aisladas, Google tarda más en descubrirlas o las considera prescindibles.
El papel del crawl budget cuando se publica en masa
El presupuesto de rastreo es la combinación entre lo que Google puede rastrear (límite de servidor) y lo que quiere rastrear (demanda). En despliegues grandes, conviene cuidar:
- Estado del host. Disponibilidad del servidor, latencias estables y ausencia de errores 5xx/4xx en picos.
- Arquitectura. Enlazado interno que descubra las nuevas URLs con pocos clics desde hubs y categorías.
- Recursos ligeros. CSS/JS no bloqueantes y compresión adecuada para no frenar al Googlebot.
- Priorización. Primero los clústeres con mayor potencial y dependencias resueltas (datos, plantillas, imágenes optimizadas).
Si en algún momento el sitio se ve saturado, es preferible pausar temporalmente (códigos 503/429 ante cargas puntuales) antes que dejar que el rastreo degrade la experiencia de los usuarios o afecte a los tiempos de respuesta.
Sitemaps para despliegues grandes (por lotes)
Para 1.000+ páginas, el sitemap y su sitemap index son el backbone del descubrimiento:
- Límites: hasta 50.000 URLs o 50 MB no comprimidos por sitemap; se pueden usar varios sitemaps y un índice que los agrupe.
- Estrategia: segmentar por tipología o por clúster temático (y/o por fecha de publicación) para poder medir en GSC cómo rinde cada lote.
- Ping/Envío: registrar el sitemap index y dejar que Google descubra el resto. Opcionalmente volver a “pinguear” cuando haya un lote nuevo.
| Elemento | Límite/Regla | Referencia |
|---|---|---|
| Tamaño por sitemap | ≤ 50 MB (sin comprimir) | Guía oficial de sitemaps |
| URLs por sitemap | ≤ 50.000 | Guía oficial de sitemaps |
| Índice de sitemaps | Hasta 50.000 <loc> (cada una apunta a un sitemap) |
Sitemap index |
Indexing API: cuándo sí y cuándo no
La Indexing API está limitada a páginas de job posting y a eventos en directo (livestream) embebidos en un VideoObject. Para el resto de proyectos, el camino recomendado es sitemaps + enlaces internos. Usarla fuera de los casos permitidos puede acarrear problemas (incluido bloqueo del servicio).
Cómo pedí la indexación y qué pasó (mi experimento)
El objetivo era simple, observar cómo reacciona Google cuando un sitio de tamaño medio publica de golpe más de mil páginas nuevas. El plan:
- Creación masiva: generé 1.000+ páginas con estructura y contenido de calidad (cada una resolvía una intención concreta).
- Enlazado interno: incorporé hubs y migas de pan y ninguna página a más de tres clics de distancia.
- Sitemaps por lotes: dividí las URLs en varios sitemaps, todos contenidos en un sitemap index, enviados en la Search Console.
- Capacidad del servidor: activé caché, compresión y medí tiempos de respuesta antes del lanzamiento.
- Monitoreo: utilicé las estadísticas de rastreo y rendimiento para medir el efecto.
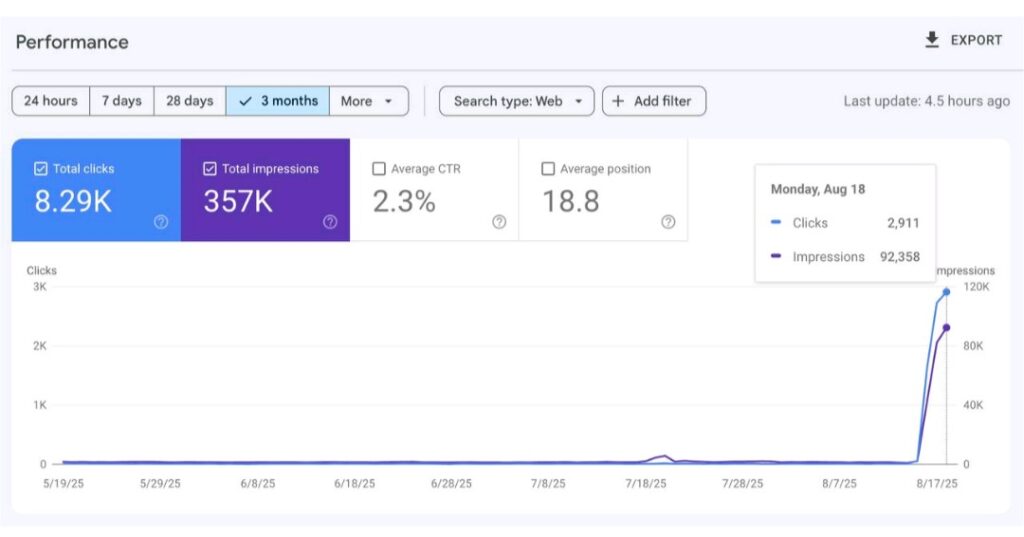
Resultado. En pocos días, vi un salto notable en páginas indexadas y tráfico orgánico.
| Métrica | Valor | Fuente |
|---|---|---|
| Páginas indexadas casi al instante | 1.300+ (del lote publicado) | Google Search Console |
| Impresiones | 357.000 | Google Search Console |
| Clics | 8.290 | Google Search Console |
El pico de impresiones llegó cuando Google descubrió y probó masivamente las nuevas URLs. La estabilización posterior dependió de la calidad y del ajuste fino de títulos/descripciones por clúster. En CTR, el primer impacto fue bajo (muchas impresiones nuevas), y fue mejorando al optimizar títulos descriptivos y enriquecer extractos.
Checklist técnico para publicar 1.000+ páginas de golpe
- Arquitectura: hubs temáticos, enlaces contextuales y migas de pan. Evitar páginas aisladas.
- Canonicals/Noindex: noindex en facetas sin valor y canonicals en variantes para cortar duplicidades.
- Sitemaps: segmentados por tipo/tema; mantenerlos actualizados y registrarlos en Search Console.
- Servidor: HTTP/2 o superior, compresión y caché activas. Supervisar errores 5xx y tiempos de respuesta.
- Medición: anotar día/hora del deployment y relacionarlo con picos en GSC. Comparar por clúster de sitemap.
- Contenido: plantillas sólidas con texto único, entidades bien definidas y datos estructurados cuando aplique.
- Rendimiento: imágenes por debajo de 100 KB y JS/CSS mínimos. Evitar recursos de terceros innecesarios.
- Registro: si hay riesgo de saturación, devolver 503 temporal en picos extremos para proteger la infraestructura.
Qué métricas monitoricé en Search Console
- Indexación de páginas: evolución del estado (Válidas/Excluidas/Con advertencias) y por sitemaps.
- Estadísticas de rastreo: solicitudes por día, peso medio, estado del host y distribución por tipo de archivo.
- Rendimiento: impresiones, clics, CTR y posición media. Recortes por clúster y por tipo de página.
- Inspección de URL: uso puntual en casos concretos, nunca como método masivo.
| Acción | Dónde | Referencia |
|---|---|---|
| Enviar sitemaps / sitemap index | Search Console > Sitemaps | Guía oficial |
| Revisar estado del host y volumen de rastreo | Search Console > Configuración > Estadísticas de rastreo | Ayuda de GSC |
| Inspeccionar URLs clave | Search Console > Inspección de URL | Cómo funciona |
Errores comunes a escala
- Etiquetas de título y H1 repetidas. Variaciones mínimas que no diferencian la intención.
- Filtros abiertos. Facetas indexables que multiplican combinaciones irrelevantes.
- Paginaciones sin rel=prev/next histórico (hoy depreciado a efectos de señales, pero la paginación debe ser clara para usuarios y robots).
- Imágenes pesadas. En catálogos, el peso de las miniaturas se dispara y frena Googlebot.
- Rutas huérfanas. Páginas nuevas sin enlaces contextuales desde contenido existente.
Preguntas frecuentes
¿Cuánto tarda Google en indexar tras un despliegue masivo?
Depende de la demanda de rastreo, la calidad del sitio y la capacidad del servidor. En mi caso, parte del lote se indexó casi al instante y el resto fue entrando en días posteriores.
¿Cuántas URLs puede llevar un sitemap?
Hasta 50.000 URLs o 50 MB no comprimidos por fichero. Es habitual usar varios sitemaps y agruparlos con un índice.
¿Conviene usar Indexing API para acelerar?
No en proyectos estándar, está pensada para job postings y livestreams. Para todo lo demás, sitemaps y buen enlazado interno.
¿Es peligroso para el servidor lanzar 1.000+ páginas de golpe?
Sólo si la infraestructura no está preparada. Con caché, compresión y monitorización de errores 5xx/429, el riesgo se minimiza. Si hay saturación, pausar (503 temporal) es mejor que dejar que caiga el sitio.
¿Cómo evité la canibalización?
Planificando clústeres semánticos desde el principio, usando títulos/descripciones únicos y un mapa de enlazado interno que refuerza a la URL principal por consulta.
¿Qué hice para mejorar el CTR tras el pico de impresiones?
Reescribí títulos con intención clara, mejoré los primeros párrafos para alinear expectativas y añadí datos específicos (entidades, números, ubicaciones) en meta descripciones.
¿Tiene sentido dividir el despliegue en tandas?
Según el caso. Si la infraestructura es modesta, escalonar por lotes (y medir en GSC por sitemap) ayuda a aprender y ajustar sin asumir todo el riesgo en un día.
¿Qué hago si parte del lote no se indexa?
Reviso el informe de Indexación de páginas por motivo, fortalezco el enlazado interno hacia esas URLs, consolido duplicidades con rel="canonical" y actualizo sitemaps. Sólo utilizo la Inspección de URL en casos puntuales y representativos.
¿Cuándo usar noindex y canonicals en despliegues a escala?
Aplico noindex a facetas/filtros sin valor de búsqueda y dejo indexables las rutas finales útiles. Uso canonicals para variantes cercanas y evito parámetros abiertos que generen combinaciones infinitas.
¿Cómo controlo que las imágenes no frenen el rastreo?
Sirvo WebP optimizadas (< 100 KB), defino dimensiones, activo lazy loading y reduzco JS/CSS bloqueantes. Si procede, uso CDN para estáticos y vigilo el peso medio por solicitud en las “Estadísticas de rastreo”.
Siguiente paso
Este enfoque funciona especialmente bien en sitios con catálogos extensos o contenido programático de alta calidad. Si el proyecto está en fase de crecimiento y hace falta ordenar arquitectura, rendimiento e indexación a escala.
Conclusión
Publicar 1.000+ páginas de golpe no es una temeridad si se aborda con método. En mi caso, la indexación masiva funcionó porque prioricé calidad, arquitectura clara y sitemaps por lotes. Preparé servidor, medí el crawl budget y enlacé internamente cada clúster. El pico de impresiones confirmó el descubrimiento, el crecimiento sostenible llegó ajustando títulos, descripciones y canónicos, y reforzando el contenido que resolvía mejor la intención.
La lección: volumen sin estrategia desperdicia rastreo, estrategia sin volumen desaprovecha oportunidades. Con medición constante en la Google Search Console y mejoras iterativas, el despliegue a escala se convierte en una palanca de tráfico y negocio.
- Todas
- Funnel De Ventas
- Diseño Web
- SEO
- Analítica Web
- Internet
- CSS
- Marketing
- Marketing Digital
- UX/UI
- Inteligencia Artificial
- Tiendas Online